



国家生物信息中心GSA突破100PB
2026年2月21日,国家生物信息中心国家基因组科学数据中心(CNCB-NGDC)组学原始数据归档库(Genome Sequence Archive,简称GSA)用户汇交的数据量突破100PB,标志着中心在生命组学数据资源规模和服务能力迈上新台阶。
从数据汇交到知识引擎
100PB数据的背后,是一个充满活力的全球科研社区。
服务覆盖全球: 截至2026年2月21日,GSA已接收来自国内外1272家研究机构、14,246名用户的数据递交,并为全球200多个国家和地区的用户提供数据服务,成为名副其实的“世界级数据枢纽”。每天,全球科学家从这里下载的数据量高达20TB,相当于传送完整的人类全基因组测序数据近7000套。
支撑创新科研: 这些数据已支撑科研人员在709种国内外期刊上发表研究论文12,000余篇。从基因发现到作物育种,从疾病机制到药物研发,GSA的数据正在转化为实实在在的科学发现和知识创新。
赢得国际信任: GSA的专业性和可靠性获得了国际主流学术界的全面认可。它不仅通过了FAIRsharing和re3data等国际权威数据标准认证,更被Springer Nature、Elsevier、Wiley、Taylor & Francis等全球顶尖学术出版集团正式采纳为推荐的基因数据归档库。2023年,GSA更是凭借其卓越的资源价值和长期可持续性,入选由国际生物数据联盟(GBC)遴选的“全球核心生物数据资源”(GCBR),标志着其已成为全球生物数据基础设施中不可或缺的一环。
构建多层次数据服务体系
突破100PB,GSA的价值不仅仅在于“大”,更在于其不断完善的“精”与“全”。为了满足国家对人类遗传资源管理和重大科研项目数据的合规需求,GSA已从单一系统扩展为一个功能强大的数据库体系:通过与INSDC(国际核酸序列数据库协作组织)合作,GSA实现了全球公开组学原始数据的全量镜像与本地化共享,整合数据规模已达25PB,让中国科学家能够像访问本地数据一样,便捷地获取全球科研资源。同时,GSA持续扩展和完善系统功能,逐步形成由GSA、GSA-Human、OBIA和OMIX构成的数据库体系,覆盖生命组学原始数据、人类遗传资源数据、生物医学影像数据及多类型科研数据,为科研用户提供整合数据的一站式检索与访问服务,为生命科学和生物医学研究提供多层次、全流程的数据支撑。
让数据智能驱动生命科学创新
站在100PB的新起点上,GSA的未来图景更加清晰。它将以成为 “数据智能驱动引擎” 为目标,持续提升核心能力:
更智能的汇交与管理: 引入AI技术,简化数据提交流程,实现数据的智能化审核与分类。
更高效的共享与治理: 优化数据搜索与计算分析功能,让科学家能像用搜索引擎一样轻松挖掘数据价值。
GSA的持续发展,离不开科技部、国家卫健委、财政部、自然科学基金委、中国科学院等国家部门的长期关怀与大力支持。正是这些战略投入与持续保障,为GSA构筑了坚实的数据基础设施和先进的算力底座。
展望未来,GSA将继续夯实生命科学的数据底座,以更高水平的数据服务能力和更开放的共享机制,赋能原始创新,为全球生命科学的进步与人类健康福祉贡献更大力量。
【关于GSA】
GSA(Genome Sequence Archive)组学原始数据归档系统致力于为全球科研界提供稳定、高效、安全的数据汇交与共享服务,是国家生物信息中心的核心数据库之一,也是支撑生命科学创新和全球生物医学研究的核心数据平台。
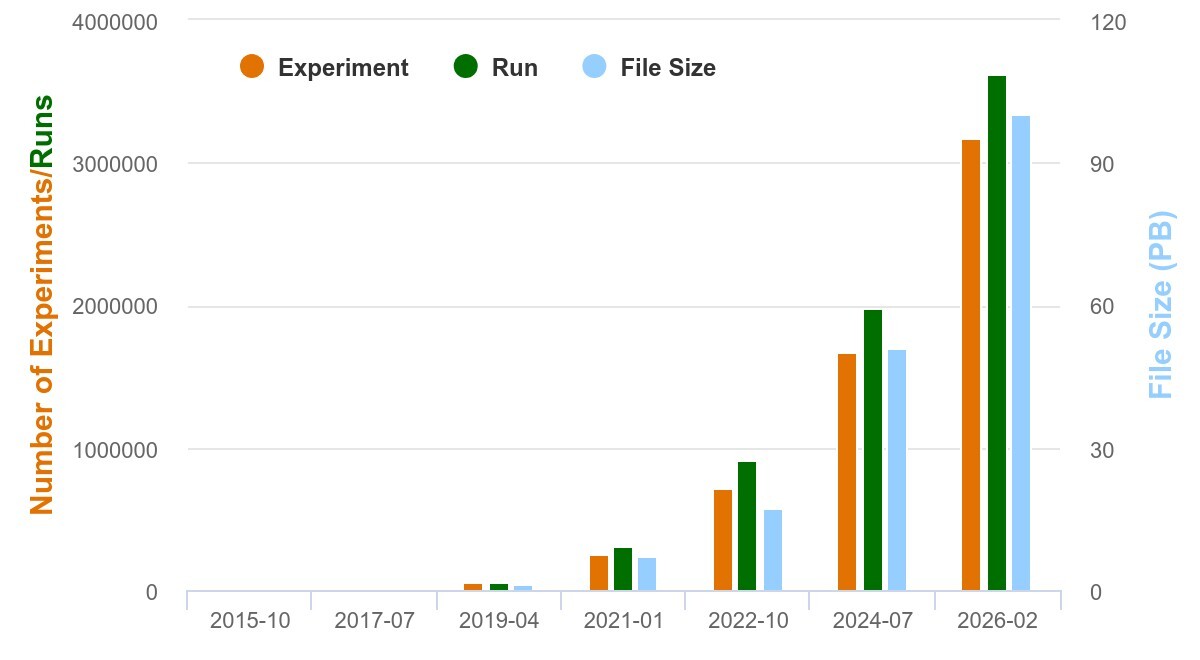
GSA数据量持续增长


