



北京基因组所(国家生物信息中心)组学原始数据归档库GSA实现与NCBI SRA数据库的数据整合
近日,在国际核酸序列数据库合作联盟(INSDC)的支持和美国国家生物信息技术中心(NCBI)的技术协助下,中国科学院北京基因组研究所(国家生物信息中心)国家基因组科学数据中心(CNCB-NGDC)完成NCBI生物项目管理数据库(BioProject)、生物样本管理数据库(BioSample)全部数据及序列片段归档库(Sequence Read Archive, SRA)全部元数据与自主开发数据库的整合,实现了上述数据在NGDC网站的一站式检索与访问,极大提升了国内科研人员查询和获取数据的效率。
CNCB-NGDC 2015年开发的组学原始数据归档库(Genome Sequence Archive, GSA)是中国首个测序数据归档系统,已完成NCBI SRA全部元数据及2022年4月20日起SRA日更新全量数据(元数据和原始序列数据)的整合。截至5月28日,GSA收录460万测序数据集,涵盖近2000万实验数据和2074多万测序反应,测序序列数据量超过13PB。特别指出的是,GSA目前提供NCBI SRA数据库全部数据的检索服务,也提供这些数据在INSDC相关数据库的下载地址以及最新数据的本地化下载地址。研究人员可以通过NGDC的跨库搜索引擎BIG Search系统,快速查找并选择最优的下载路径获取数据。
GSA正在逐步下载整合NCBI SRA中的历史数据,实现全球生命组学测序数据的本地化管理,为国内科研人员提供数据获取便利的同时,也为全球生命组学数据共享贡献力量。

BIG-Search检索系统中可实现国际来源数据检索
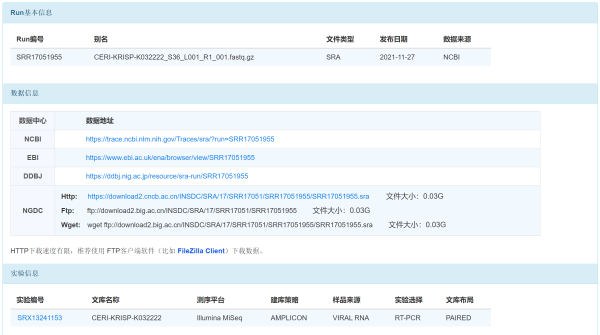
GSA页面整合国际来源数据下载地址
附件下载:


