



北京基因组所(国家生物信息中心)数据资源建设取得阶段性进展
 11月11日,中国科学院北京基因组研究所(国家生物信息中心)国家基因组科学数据中心(CNCB-NGDC)在国际学术期刊《核酸研究》(Nucleic Acids Research)在线发表题为“Database Resources of the National Genomics Data Center, China National Center for Bioinformation in 2021”的文章,以整体形式介绍基因组数据资源整合与挖掘体系建设方面的布局与进展。
11月11日,中国科学院北京基因组研究所(国家生物信息中心)国家基因组科学数据中心(CNCB-NGDC)在国际学术期刊《核酸研究》(Nucleic Acids Research)在线发表题为“Database Resources of the National Genomics Data Center, China National Center for Bioinformation in 2021”的文章,以整体形式介绍基因组数据资源整合与挖掘体系建设方面的布局与进展。
2020年,CNCB-NGDC与共建单位及合作单位密切合作,开发了6个全新数据库(新型冠状病毒信息库2019nCoVR,Aging Atlas,BrainBase,GTDB,LncExpDB和TransCirc),更新和丰富了多个核心数据库资源(BioProject,BioSample,GSA,GWH,GVM,GEN和生物多样性数据资源等),涉及衰老、疾病、调控和生物多样性等多个前沿领域,初步形成我国生物数据安全汇交管理和多组学数据平台的国家中心数据资源体系。1月22日,CNCB-NGDC率先发布了新型冠状病毒信息库,并始终保持全球最新、最完整的新冠病毒基因组数据发布动态,累计全球访问量近百万。此外,基于Elasticsearch技术升级开发了生物大数据搜索引擎BIG Search,系统整合了中心、EBI、NCBI和8个合作机构的38个重要数据资源,实现海量、异构生物数据的一站式跨库高效检索。
CNCB-NGDC免费向国内外用户提供方便快捷的多组学数据汇交和存储服务。目前已汇交来自331个单位1192个用户递交的超过5.4PB的组学数据,相关数据发表于187种国内外期刊的409篇文章。GSA已被国际著名出版商Elsevier收录为指定的基因数据归档库。2020年1月1日以来,CNCB-NGDC公共数据平台访问量超过188万人次。
该工作得到科技部、中国科学院、自然科学基金委、一带一路国际科学组织联盟、国际生物科学联合会等的资助。
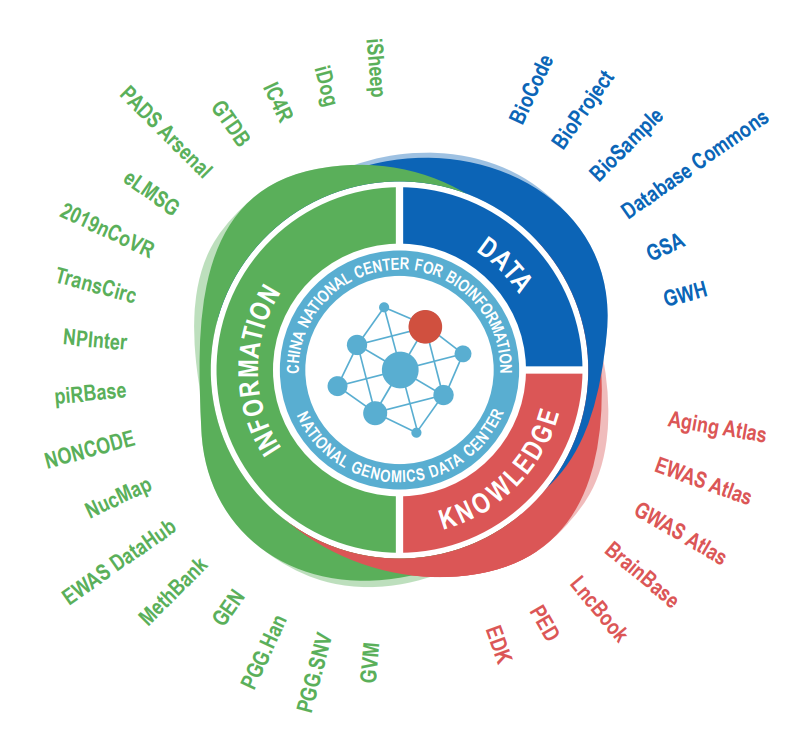
国家生物信息中心-国家基因组科学数据中心数据资源


