



北京基因组所(国家生物信息中心)发布更新版人类长非编码RNA数据库LncBook 2.0
近日,由中国科学院北京基因组研究所(国家生物信息中心)国家基因组科学数据中心开发的人类长非编码RNA(long non-coding RNA, lncRNA)数据库LncBook 2.0正式上线。该研究内容以“LncBook 2.0: integrating human long non-coding RNAs with multi-omics annotations”为题在国际学术期刊Nucleic Acids Research 在线发表。
LncRNA是哺乳动物基因组中的重要组成部分,参与DNA甲基化、组蛋白修饰、转录调控、转录后调控等多个生物学过程,与人类疾病的产生和发展密切相关。LncBook数据库致力于人类lncRNA数据整合,并通过多组学数据分析对lncRNA进行系统注释。自2019年发布以来,LncBook数据库在描绘人类lncRNA的转录图谱、挖掘lncRNA分子特征以及揭示lncRNA与疾病关系等方面被广泛应用。
LncBook2.0收录了119722个新的转录本,注释了9632个新的基因,更新了21305个lncRNA基因的结构。丰富的多组学数据是LncBook2.0的一大亮点,包括保守性、表达、DNA甲基化、变异、小蛋白、相互作用六个方面。通过与40种脊椎动物比较,LncBook2.0刻画了人类lncRNA基因的保守性,并在这些物种中鉴定出了139306个蛋白编码及非编码同源基因。表达数据方面,相比1.0版本,LncBook2.0收录的表达谱数据涉及的生物学场景从1种增加到了9种,包含器官发育、细胞分化、亚细胞定位等。而在甲基化数据方面,LncBook2.0涉及到的疾病类型从9种癌症增加到了14种癌症和2种神经系统发育疾病。此外,LncBook2.0收集了959138条与疾病/性状相关的变异信息和34012个lncRNA编码的小蛋白,鉴定了772745条lncRNA-蛋白质相互作用并预测了146092274条lncRNA-miRNA相互作用。
LncBook2.0数据库具备友好的检索、浏览与可视化功能,方便用户通过不同基因/转录本ID、基因symbol进行检索和浏览。用户可以在多组学页面中通过排序、筛选功能过滤出符合条件的lncRNA基因,随后在单个lncRNA基因的页面中查看它的转录本、编码潜能、保守性等信息。LncBook2.0还与团队之前开发的LncRNAWiki和LncExpDB数据库进行了关联,用户在浏览lncRNA基因信息时可以通过链接跳转到相关页面,查看该基因的更多信息。
北京基因组所(国家生物信息中心)博士研究生李昭、特别研究助理刘琳、硕士研究生冯昶瑞为本文共同第一作者,马利娜副研究员与章张研究员为共同通讯作者。该研究得到了中科院战略性先导科技专项、国家重点研发计划、中科院青促会等项目资助。
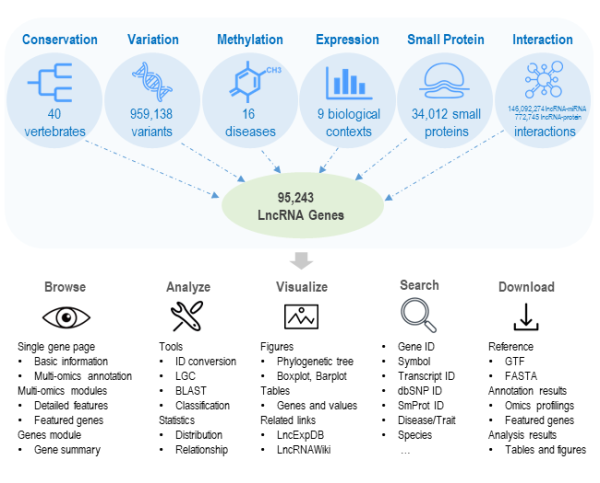
LncBook 2.0数据库内容与功能
附件下载:


