



国家生物信息中心合作研究基因组DNA语言模型被ICLR 2026收录
人工智能领域国际顶级会议 ICLR 2026 收录了国家生物信息中心的最新研究成果 AntigenLM。该工作聚焦于探索如何将生成式人工智能与病毒基因组结构先验深度融合,从而实现对流感抗原进化的高精度预测与亚型判别。
AntigenLM 提出了一种结构感知的 DNA 语言模型。模型以自回归 Transformer 为骨干,在预训练阶段直接建模完整流感病毒基因组,显式保留八个基因片段的功能单元结构与顺序信息,从而学习跨基因片段的高阶协同进化约束。在微调阶段,模型进一步引入 sentinel 标记,对不同功能区域进行显式边界建模,引导模型注意力聚焦于抗原区域。基于这种结构感知预训练 + sentinel 引导微调 + 条件自回归生成的统一建模框架,AntigenLM 能够利用连续时间窗口内的历史 HA/NA 序列,生成未来可能流行的抗原序列;同时,通过共享模型骨干,还可高效支持亚型分类等判别任务。
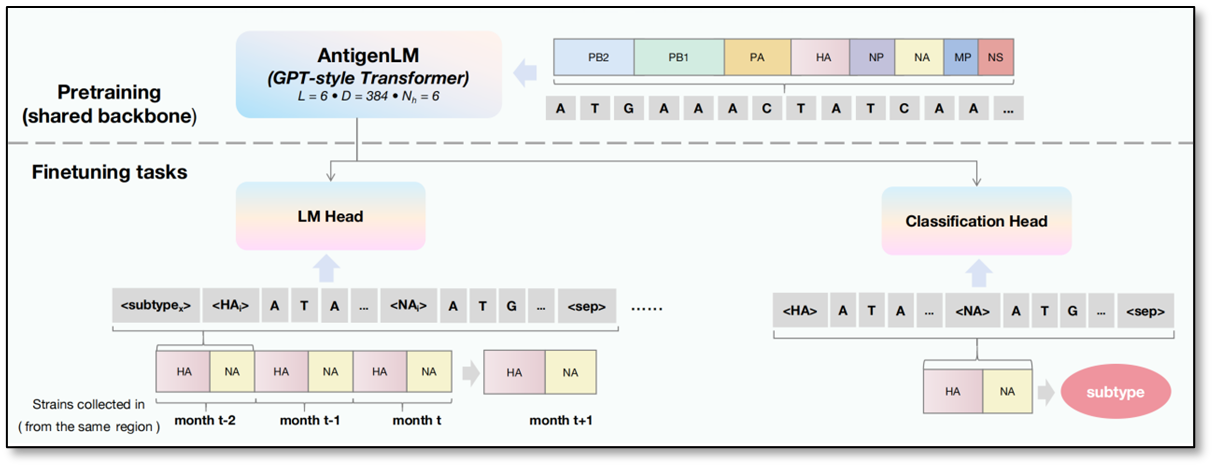
AntigenLM 架构:预训练与微调阶段的示意图
在下一流行季流行毒株预测(疫苗株选择相关)中,AntigenLM无论在 H1N1 还是 H3N2,在全长基因和抗原表位中均取得最低错配率,其中 H1N1-HA 和 H3N2-NA 的提升最为显著:相较 WHO 当前疫苗推荐株,错配率降低 >70%,相较SOTA抗原预测模型 beth-1 降低 ~50%,抗原表位仅有 0–1 个氨基酸错配。此外,AntigenLM 在未见亚型和地域测试中表现出良好的跨亚型与跨地域鲁棒性,并在测试案例中 90% 正确预测分支转换,符合已知抗原漂移规律,显示出未来基于合成生物学的疫苗设计指导潜力。此外,在流感 A 多亚型分类任务中,AntigenLM 取得了 99.81% 的 F1 分数,显示出其学习到的表示具有高度的生物学一致性与良好的泛化能力。
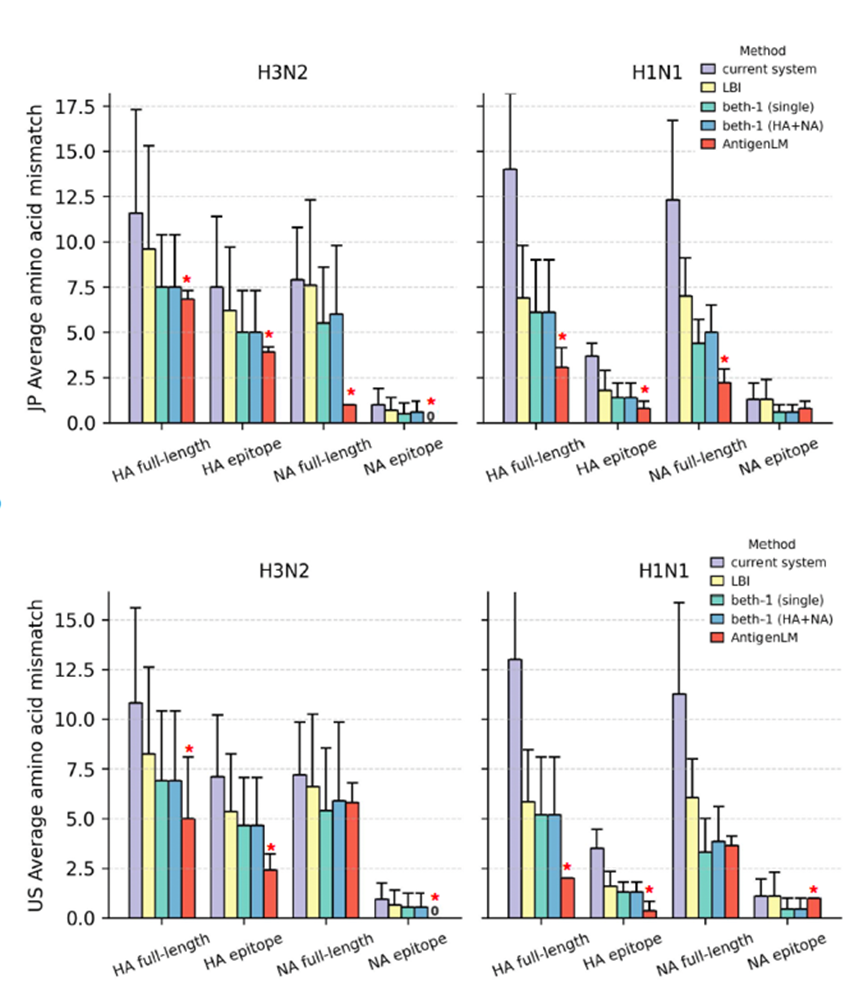
AntigenLM 在所有预测任务中实现最低的氨基酸错配率
该研究展示了生物学结构本身可以作为一种有效的归纳偏置被系统性引入基础模型设计中。AntigenLM为 AI 驱动的病毒进化预测、疫苗设计及计算基因组学研究提供了新的方法学参考,展示了人工智能与生命科学深度交叉融合的潜力。
该文第一作者为中国科学院计算机网络信息中心博士生裴月,通信作者为国家生物信息中心康禹研究员,联合通信作者为计算机网络信息中心迟学斌研究员。


