近日,中国科学院北京基因组研究所生命与健康大数据中心开发了国际领先、国内首个规模最大的基因组序列变异库—GVM(Genome Variation Map)。该库基于人工审编整合了多个物种的大量基因组序列单核苷酸多态位点和小的插入与删除变异信息,是基因组序列变异信息汇交、管理与检索的资源库。研究成果以“Genome Variation Map: a data repository of genome variations in BIG Data Center”为题在国际学术期刊Nucleic Acids Research在线发表。
基因组序列变异是基因组DNA水平发生的可遗传变异,是生物多样性的基础,是物种进化、分子育种、优良性状选育、人类疾病等研究最为宝贵的遗传资源。近年来,随着测序技术发展,越来越多物种的基因组被精细解析;物种内遗传多态变异位点也通过大规模的群体测序获得,并广泛应用于复杂性状的关联解析。国际两大数据中心NCBI和EBI旗下的dbSNP和EVA是两个主要的基因组序列变异资源库。今年5月,NCBI宣布自2017年9月1日起,dbSNP和dbVar两大数据库停止接收非人物种的SNP提交信息,自2017年11月1日起停止非人物种的SNP在线查询与提交。对基于序列变异研究的科研人员造成了极大不便。
为此,GVM作为生命与健康大数据中心的核心数据资源库之一,搜集了以二代测序和芯片技术为主要检测手段的全基因组序列变异检测的原始数据,通过标准化的变异位点鉴定与注释,获得包括人、畜牧动物、主要农作物和其他资源物种在内的19个物种共约50亿的变异信息,8,884个个体的基因型数据,并通过人工审编收录了13,262条高质量非人物种的基因型与表型知识数据、整合了180,911条人变异位点的知识信息。其中,大熊猫、虎鲸、毛竹、橡胶、小麦是GVM数据库所特有的物种。
GVM开发了友好的数据提交、浏览、搜索和可视化功能。用户可通过基因组位置、变异影响、基因名称和基因功能等检索变异位点信息,下载数据,也可通过ftp服务下载VCF和FASTA文件格式的全基因变异信息,可以在线或离线方式向系统提交数据,极大方便了科研人员的数据共享。
该研究得到了中国科学院战略性先导科技专项、中国科学院国际大科学计划、国家科技攻关计划、国家863计划、国家自然基金项目、中科院青年创新促进会等项目基金的资助。
论文链接
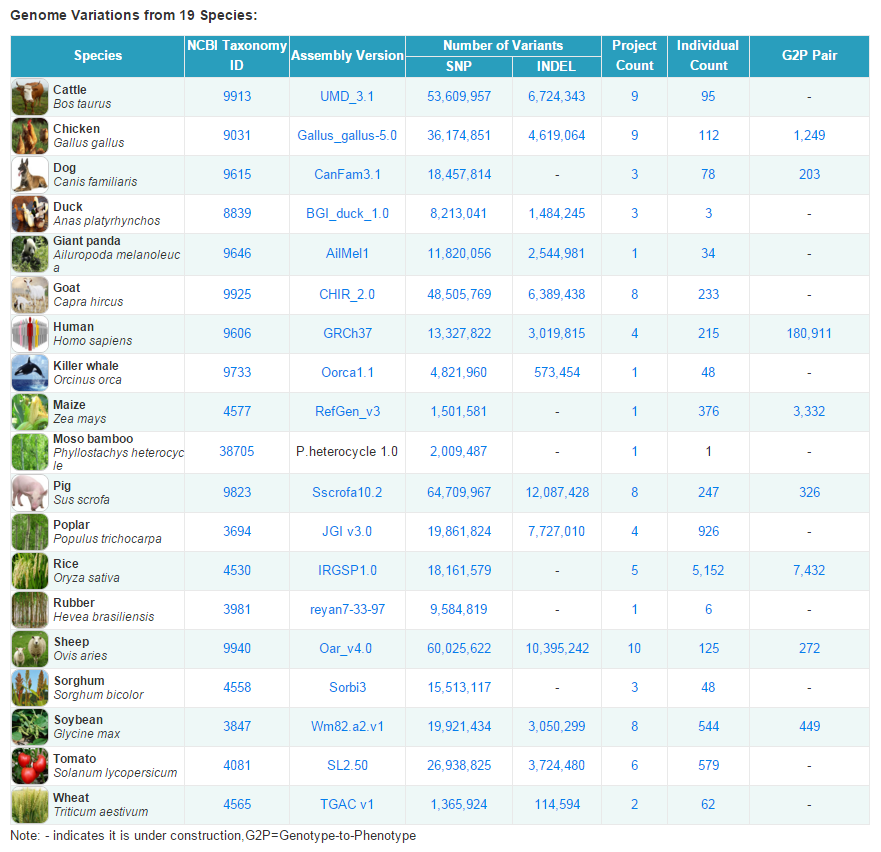
GVM数据库物种变异信息统计表


